서비스(방문 트래픽, 이메일, 마케팅 등)의 운영에 필요한 데이터를 저장하는 곳(쇼핑몰 같은 곳)
빠른 처리속도가 중요함
vs(반대). 데이터 웨어하우스 관계형 데이터베이스
백엔드 개발자이건 프런트 개발자이건 잘 알아야 하는 기본 기술
프로덕션 관계형 데이터베이스란?
대표적으로 MySQL, PostgreSQL, Oracle이 있으며 OLTP (Oneline Transacion Processing): 빠른 속도에 집중, 서비스에 필요한 정보 저장
대표적으로 MySQL
데이터 웨어하우스란?
데이터를 빠르게 처리하는 것보단 얼마나 큰 데이터를 처리할 수 있는냐에 초점을 맞춘 것
회사 관련 데이터를 저장하고, 분석함으로써 의사결정과 서비스 최적화에 사용
OLAP (Online Analytical Processing)
처리 데이터 크기에 집중, 데이터 분석 혹은 모델 빌딩등을 위한 데이터 저장
프로덕션 데이터베이스를 복사해서 데이터 웨어하우스에 저장
관계형 데이터베이스: 구조화 된 데이터
비관계형 데이터베이스: 비구조화 데이터
흔히 NoSQL 데이터베이스라고 부름.
프로덕션용 관계형 데이터베이스를 보완하기 위한 용도
2. 백엔드 시스템 구성도
개발 직군
프론트엔드
사용자와 상호작용을 하는 부분으로, UI(보통 웹브라우저, 스마트폰에 사용자에게 노출되는 서비스)
백엔드
사용자에게 보이지 않지만, 실제 데이터를 저장/추가하고 사용자가 요구한 일을 수행하는 부분, 데이터를 저장하기 때문에 다양한 데이터베이스들이 사용됨
데브옵스(DevOps)
주로 백엔드에 집중을 두고 서비스의 운영을 책임지는 팀
풀스택(Fullstack)
프런트/백엔드 둘 다 할 수 있는 개발자
데이터 직군: 데이터의 중요성이 증대되면서 3가지 데이터 직군이 등장
MLOps (인공지능 특화)
데이터 분석가: 데이터 웨어하우스를 기반으로 다양한 지표설정과 분석 수행
데이터 과학자: 과거 데이터를 기반으로 미래를 예측하는 모델링 혹은 개인화 작업으로 서비스의 만족도를 높이고 프로세스의 최적화를 수행
시스템 구성의 변화
2 tier
Server와 Client 두개의 티어로 구성
클라이언트는 사용자가 사용하는 UI
서버가 데이터베이스가 됨.
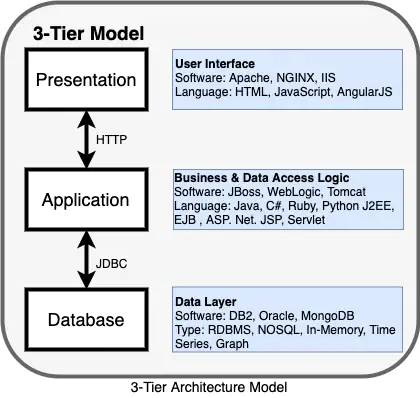
3 tier
웹 서비스에서 많이 사용되는 아키텍쳐
프레젠테이션 티어: 프론트
애플리케이션 티어: 백엔드
데이터 티어: 백엔드
3. 관계형 데이터베이스
Customers 테이블
아이디이름이메일
white
나상원
white@white.com
Sales 테이블
아이디구매일상품명
white
2021-08-10
버섯
서로 다른 테이블이지만, 아이디 필드는 관계가 서로 같아 관계형 데이터베이스로 명령어로 물어보면 대답해준다.
구조화된 데이터를 저장하고 질의할 수 있도록 해주는 스토리지
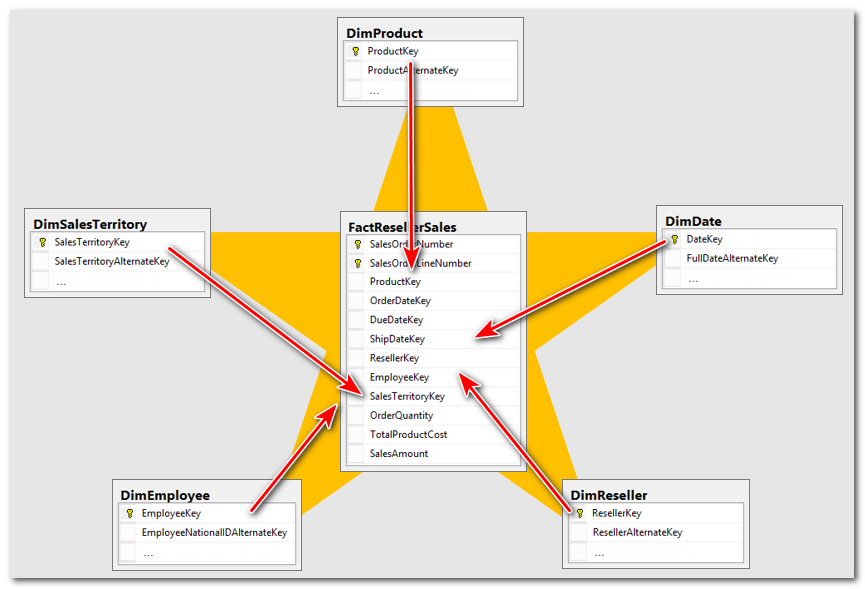
서로 서로 관계가 이어진 모습이 별처럼 보인다고 하여 스타 스키마 (Star schema)라고 부릅니다.
Production DB용 관계형 데이터베이스에서는 보통 스타 스키마를 사용해 데이터를 저장
데이터를 논리적 단위로 나눠 저장하고 필요 시 조인(합치다)
스토리지의 낭비가 덜하고 업데이트가 쉬움(필요한 부분만 조립하면 되기 때문에)
반대의 데이터 구조 - Denormalized schema
NoSQL이나 데이터 웨어하우스에서 사용하는 방식
단위 테이블로 나눠 저장하지 않음으로 별도의 조인이 필요 없는 형태를 말함(ex: 나이, 성별, 주민번호 등으로 나눠서 저장하지 않고 한곳에 몰아서 저장)
스토리지를 더 사용하지만, 조인이 필요 없기에 빠른 계산이 가능
관계형 데이터베이스를 조작하는 프로그래밍 언어가 SQL
테이블 정의를 위한 DDL(Data Definition Langeuage)
테이블의 포맷을 정의해주는 언어
테이블 데이터 조작/질의를 위한 DML(Data Manipulation Language)
DDL로 정의된 테이블에 레코드를 추가, 수정, 삭제 혹은 읽어들이기 위해 사용하는 언어
테이블들은 데이터베이스(스키마)라는 폴더 밑에 구성(엑셀 파일에 해당)
테이블의 구조(테이블 스키마)
테이블은 레코드들로 구성 (행)
레코드는 하나 이상의 필드(컬럼)으로 구성 (열)
가장 밑단에는 테이블들이 존재 (엑셀의 시트에 해당)
4. SQL 소개
SQL: Strucured Query Language (구조화된 질의 언어)
관계형 데이터베이스에 있는 데이터(테이블)를 질의하거나 조작해주는 언어
구조화(틀)에 맞춰서 데이터들이 저장되어 있으니, 질의(질문)을 어떻게 하냐에 따라 저장된 데이터를 가져올 수 있다.
"아이디 '홍길동'인데 성별은 남자의 정보를 보여줘" 라고 구조화(정해진 순서)에 맞춰 질의를 하게 되면 데이터베이스에 저장된 값을 볼 수 있다.
구조화된 데이터로 다루기 힘든 데이터는 비구조화 데이터를 다루는데 필요한 데이터베이스가 필요하게 되었는데, 이에 Spark, Hadoop과 같은 분산 컴퓨팅 환경도 존재함.
SQL 기본
질의하는 SQL문은 세미콜론으로 분리 구분
sql; sql;
-- 주석은 하이픈 2개
/* 단위 주석*/
SQL 데이터 언어
DDL(데이터 정의 언어)
CREATE TABLE table_name;
테이블을 생성 할 때 사용
Primary key 속성 지정 가능
성능향상을 위해 인덱스 지정
DROP TABLE table_name;
테이블을 지울 때 사용
없는 테이블을 지우려고 할 시 에러
ALTER TABLE
ALTER TABLE 테이블이름 ADD COLUMN 필드이름 필드타입; // 새로운 컬럼 추가
ALTER TABLE 테이블이름 RENAME 현재필드이름 TO 새필드이름
ALTER TABLE 테이블이름 DROP COLUMN 필드이름
ALTER TABLE 현재테이블이름 RENAME to 새테이블이름;
DML(데이터 조작 언어)
레코드 질의 언어: SELECT
WHERE 레코드 선택 조건
GROUP BY 그룹 (필드)레벨 선택 조건
ORDEY BY 레코드 순서
레코드 추가/삭제/수정
INSERT INTO (추가)
UPDATE FROM (수정)
DELETE FROM (삭제)
vs. TRUNCATE (모든 레코드 삭제)
MySQL 소개
1955년 스웨덴 회사였던 MySQL AB에 의해 개발된 관계형 데이터베이스 * 오픈소스로 시작됨(무료)
My는 개발자 중 한 사람의 딸의 이름이었음.
2008년 썬 마이크로시스템가 MySQL AB를 $1B을 주고 인수
2009년 오라클이 썬을 인수하면서 MySQL이 유료화 여부가 쟁점이 됨
2010년 MySQL의 처음 개발자였던 Monty가 MySQL과 호환이 되는 MariaDB라는 오픈소스 개발
MySQL 종류와 버전
MariaDB * 오픈소스로 무료, MySQL 5.5에 기반해서 개발됨, MySQL과 인터페이스는 동일하나 성능은 더 좋음
MySQL
두 가지 종류가 존재 * MySQL Community Server: 오픈소스로 무료. 우리가 사용해볼 버전
MySQL Enterprise Server: 유료 버전으로 다양한 플러그인 제공
MySQL 특징
한동안 웹개발 표준 기술 스택 중 하나 * LAMP: Linux, Apache, MySQL, PHP
Postgres와 함께 가장 널리 쓰이는 프로덕션용 관계형 데이터베이스
용량 증대(Scaling) 방식 1 *Scale-Up: 서버에 CPU와 Memory 추가
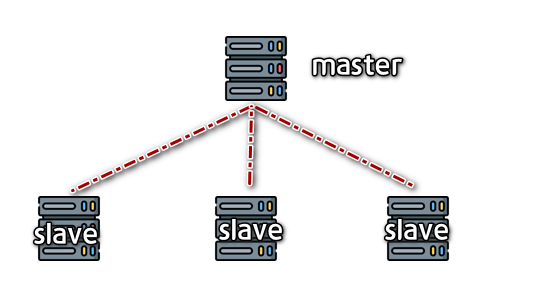
용량 증대 (Scaling) 방식 2 *Scale-Out: Master-Slave 구성
읽기 작업만 Master를 통해 Slave에서 읽어옴. 따라서 읽기에 대해선 용량 증대 효과를 얻을 수 있음.
쓰기작업은 Master에만 할 수 있음.
일반적으로 Scale-Out은 클러스터 구성을 이야기 하나 MySQL은 이를 지원하지 못함.
클라우드
1. 클라우드의 정의
컴퓨팅 자원(하드웨어, 소프트웨어 등등)을 네트웍을 통해 서비스 형태로 제공
키워드 "No Provisioning" 프로비저닝은 사용자의 요구에 맞게 시스템 자원을 할당, 배치, 배포해 두었다가 필요 시 시스템을 즉시 사용할 수 있는 상태로 미리 준비해 두는 것을 말한다. "Pay As You Go" 사용한 만큼 지불하고 사용하는 것을 말한다.
자원을 필요한 만큼 실시간으로 할당하여 사용한 만큼 지불
탄력적으로 필요한 만큼의 자원을 유지하는 것이 중요
2. 클라우드 컴퓨팅이 없다면?
서버/네트웍/스토리지 구매와 설정 등을 직접 수행
데이터센터 공간을 직접 확보
서버를 직접 구매하고 설치(네트웍 설정)
보통 서버를 구매하는 경우 두세달은 걸림
확장이 필요한 경우, 서버보단 공간을 먼저 확보해야함.
Peak time을 기준으로 Capacity planning을 해야합니다. * 놀고 있는 자원들이 존재
3. 클라우드 컴퓨팅의 장점
초기 투자 비용이 크게 줄어듬
CAPEX(Capital Expenditure) vs OPEX(Operating Expense)
예산이 적어서 재무팀이랑 싸울 일이 없다.
리소스 준비를 위한 대기시간 대폭 감소
노는 리소스 제거로 비용 감소
글로벌 확장 용이(리전이 전세계 곳곳에 있음)
소프트웨어 개발 시간 단축
Managed Service (SaaS) 이용
3.1 AWS 소개
가장 큰 클라우드 컴퓨팅 서비스 업체
다양한 종류의 서버 구매옵션 제공
On-Demand: 시간당 비용을 지불하며 가장 흔히 사용하는 옵션
Reserved: 1년이나 3년간 사용을 보장하고 1/3 정도에서 40% 디스카운트를 받는 옵션
Spot Instance: 일종의 경매방식으로 놀고 있는 리소스들을 보다 싼 비용으로 사용 할 수 있는 옵션
EC2 - Elastic Cloud Compute
AWS의 서버 호스팅 서비스
리눅스 혹은 윈도우 서버를 론치하고 로그인 가능
가상 서버들이라 전용서버에 비해 성능이 떨어짐
Bare-metal 서버도 제공하기 시작
S3 - Simple Storage Service
아마존이 제공하는 대용량 클라우드 스토리지 서비스
S3는 데이터 저장관리를 위해 계층적 구조를 제공
글로벌 네임스페이스를 제공하기 때문에 탑레벨 디렉토리 이름 선정에 유의
S3에서는 디렉토리를 버킷(Bucket)이라고 부름
버킷이나 파일별로 액세스 컨트롤 가능
4. Database Services
RDS(Relational Database Service)
MySQL/MariaDB, PostgreSQL, Aurora
AWS에서 제공하는 Redshfit
AI & ML Services
SageMaker
Lex
Polly
Rekognition
기타 중요 서비스
Amazon Alexa(아마존 보이스 봇), Amazon Connect(콜센터 구현)
Lambda
5. Docker란 무엇인가?
도커는 리눅스의 응용 프로그램들을 프로세스 격리 기술들을 사용해 컨테이너로 실행하고 관리하는 오픈 소스 프로젝트이다. 도커 웹 페이지의 기능을 인용하면 다음과 같다: 도커 컨테이너는 일종의 소프트웨어를 소프트웨어의 실행에 필요한 모든 것을 포함하는 완전한 파일 시스템 안에 감싼다. MySQL를 다른 OS에서 설치하려면 다양한 변수가 존재
Virtualization vs Containerization
Docker Engine으로 컨테이너화 시켜서 패키지 프로그램등을 가상화로 돌릴 수 있습니다.
6. DDL과 데이터 소개
관계형 데이터베이스 예제 - 웹서비스 사용자/세션 정보
사용자 ID: 웹서비스에서는 등록된 사용자마자 부여하는 유일한 ID
세션 ID: 세션마다 부여되는 ID
세션: 사용자의 방문을 논리적인 단위로 나눈 것
사용자가 외부링크를 타고 오거나 직접 방문해서 올 경우 세션을 생성
사용자가 방문 후 30분간 상호작용이 없다가 뭔가를 하는 경우 새로 세션을 생성
하나의 사용자는 여러 개의 세션을 가질 수 있음.
보통 세션의 경우 세션을 만들어낸 터치포인트=접점(경유지)를 채널이란 이름으로 기록해둠.
마케팅 관련 기여도 분석을 위함.
관계형 데이터베이스 예제: 우리가 저장하고 싶은 데이터
prod 데이터베이스
1. session 테이블
컬럼타입부가설명예
id
int
세션 ID
101 (기본키)
user_id
int
사용자 ID
201
created
timestamp
세션 생성시간
2021-05-01 11:32:59
channel_id
int
채널 ID
1 (Foreign Key)
2. channel 테이블
컬럼타입설명
id
int
session 테이블 channel_id의 Primary Key
channel
varchar(32)
외부키
테이블 필드의 중요 속성
PRIMARY KEY
테이블에서 레코드의 유일성을 정의하는 필드: 그것이 primary key(예: 이메일, 주민번호)
Composite(합성) primary key: primary key가 두개 혹은 그 이상의 필드로 정의되는 경우
Primary key로 지정된 필드가 있는 경우 데이터베이스단에서 중복된 값을 갖는 레코드가 생기는 것을 방지함: primary key uniqueness constraint(제약)
Foreign key
테이블의 특정 필드가 다른 테이블의 필드에서 오는 값을 갖는 경우
NOT NULL
필드의 값이 항상 존재해야하는 경우 (비어있는 값에 null로 초기화되는데 이걸 not null로 선언하면 null이 아니라 값을 무조건 저장하게끔)
DEFAULT value
필드에 값이 주어지지 않은 경우 기본값을 정의해줌
timestamp 타입: CURRENT_TIMESTAMP를 사용하면 현재 시간으로 설정됨.
관계형 데이터베이스 예제: channel table DDL
CREATE TABKE channel (
id int not null auto_increment primary key,
channel varchar(32) not null
);
// primary key는 뒤로 빼서 입력하는게 범용적
CREATE TABLE channel (
id int not null auto_increment,
channel varchar(32) not null,
primary key(id)
);
CREATE TABLE session (
id int not null auto_increment primary key,
user_id int not null,
created timestamp not null default current_timestamp,
channel_id int not null,
foreign key(channel_id) references channel(id)
);
// [테이블channel]의 id값을 [테이블session]의 channel_id를 참조하여 foreign key로 설정
최대 50글자까지 넣을 수 있는 필드가 필요한데, 보통 3~4글자만 들어간다면 매번 50글자까지 넣을 수 있게 용량을 차지하면 낭비되는걸 방지하려면 VARCHAR를 쓰면 됩니다. 하지만 속도면에서는 CHAR보단 느립니다.
VARCHAR는 문자당 1바이트, + 2바이트를 사용하여 길이 정보를 보유합니다
JSON Type
다양한 JSON 조작함수를 제공함
Spatial Type
위도와 경도를 중심으로 한 위치 관련 타입
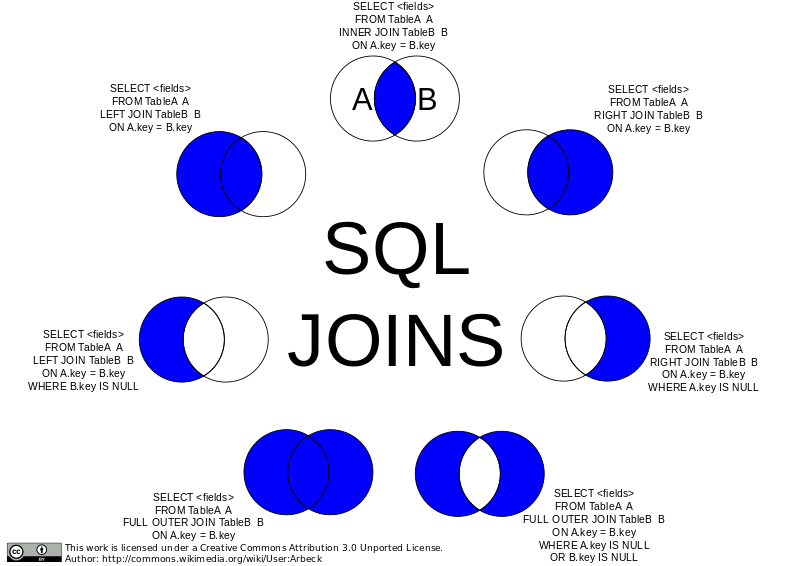
다양한 JOIN 살펴보기
JOIN이란?
SQL조인은 두 개 이상의 테이블들을 공통 필드를 가지고 통합
스타 스키마로 구성된 테이블들로 분산되어 있던 정보를 통합하는데 사용
JOIN 결과로 양쪽의 필드를 모두 가진 새로운 테이블로 만들어짐
어떤 레코드로 선택되는지?, 어떤 필드들이 채워지는지?
INNER JOIN
LEFT/RIGHT JOIN
OUTER JOIN
CROSS JOIN
SELF JOIN
트랙잭션 소개
트랜잭션이란?
테이블 내용을 변경하는 SQL들이 연달아 실행되며, 마치 하나의 SQL처럼 다 같이 성공하던지 아니면 실패해야 한다면 트랜잭션의 사용이 필수!
Atomic(하나의 시퀀스)하게 실행되어야 하는 SQL들을 묶어서 하나의 작업처럼 처리하는 방법
DDL이나 DML 중 레코드를 수정/추가/삭제 한 것에만 의미가 있음.
SELECT에는 트랙잭션을 사용할 이유가 없음.
BEGIN과 END 혹은 BEGIN과 COMMIT 사이에 해당 SQL들을 사용
ROLLBACK
트랙잭션 예시
은행 계좌 이체
계좌 이체: 인출과 입금의 두 과정으로 이뤄짐
만일 인출 성공했는데 입금이 실패한다면?
이 두 과정은 동시에 성공하던지 실패해야함 -> Atomic하다는 의미
이러한 두 과정을 하나로 묶어서 실행하는걸 트랙잭션이라 함.
BEGIN; -- START TARNSACTION
A의 계좌로부터 인출;
B의 계좌로 입금;
END; -- COMMIT
BEGIN과 START TRANSACTION은 같은 의미
END와 COMMIT은 동일
만일 BEGIN 전의 상태로 돌아가고 싶다면 ROLLBACK 실행
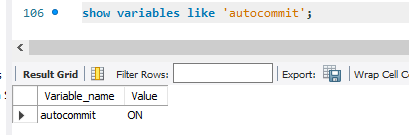
이 동작은 autocommit 모드에 따라 달라짐.
autocommit = True // ON
모든 레코드 수정/삭제/추가 작업이 기본적으로 바로 DB에 쓰여짐. 이를 커밋(Commit)된다고 함.
만일 특정 작업을 트랜잭션으로 묶고 싶다면 BEGIN과 END(COMMIT)/ROLLBACK으로 처리
autocommit = False // OFF
모든 레코드 수정/삭제/추가 작업이 COMMIT이 호출될 때까지 커밋되지 않음.
명시적으로 커밋을 해야함.
ROLLBACK이 호출되면 앞서 작업들이 무시됨
-- autocommit 작동 방법
SHOW VARIABLES LIKE 'AUTOCOMMIT';
-- autocommit 변경 방법
SET autocommit = 0 --(혹은 1)로 작동 변경가능
DELETE FROM vs TRUNCATE 차이
테이블 안에 내용을 모두 삭제하지만, TRUNCATE는 WHERE를 사용해 특정레코드는 삭제 불가능, 그래서 TRUNCATE 테이블명 으로 사용
DELETE FROM는 속도가 느림
TRUNCATE는 Transaction을 지원하지 않음.
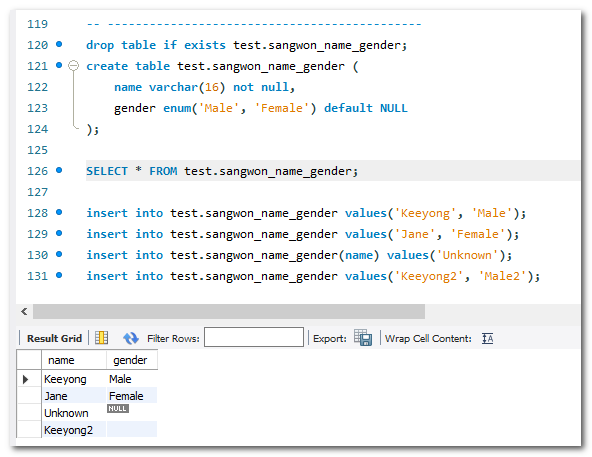
default를 null로 줬기 때문에, 따로 Values(인자)를 주지 않으면 NULL값이 들어갑니다.
4번째 INSERT의 'Male2'은 enum에 없는 값이 들어갑니다. 따라서 enum에 열거되어있지 않기 때문에 빈 값이 들어갑니다.
빈 문자열은 대신 특수 오류 값으로 삽입됩니다. 이 enum으로 만든 필드의 문자열은 숫자 값 0을 가지고 있어 "일반" 빈 문자열과 구별 될 수 있습니다. 예시) ENUM('Mercury', 'Venus', 'Earth')
View 소개
View란? 자주 사용하는 SQL 쿼리(SELECT)에 이름을 주고 그 사용을 쉽게 하는 것
이름이 있는 쿼리가 View로 데이터베이스단에 저장됨.
SELECT 결과가 테이블로 저장되는 것이 아니라 View가 사용될 때마다 SELECT가 실행됨.
때문에 가상 테이블이라고 부르기도 함(Virtual Table)
CREATE OR REPLACE VIEW 뷰이름 AS SELECT ...
Stored Procedure, Trigger 소개
Stored Procedure란?
View의 가상테이블처럼 MySQL 서버단에 저장되는데, View보다 훨씬 강력한 기능 제공
CREATE PROCEDURE 사용
DROP PROCEDURE [IF EXISTS]로 제거
프로그래밍 언어의 함수처럼 인자를 넘기는 것이 가능, INOUT 지원
리턴되는 값은 레코드들의 집합
간단한 분기문(if, case)과 루프(loop)를 통한 프로그램이 가능
디버깅이 힘들고 서버단의 부하를 증가시킨다는 단점 존재
정의 문법
DELIMITER //
CREATE PROCEDURE procedure_name(parameter_list)
BEGIN
statements;
END //
DELIMTER;
DELIMITER 다음에 나오는 문자(//)는 $$등 아무거나 해도 됨. 다음 문자(//) 나올때까지 안에 내용을 Sotred 저장해서 사용한다는 의미
호출 문법
CALL stored_procedure_name(argument_list);
Stored function이란?
값(Scalar)을 하나 리턴해주는 서버쪽 함수(특정 데이터베이스 밑에 등록됨)
리턴값은 Deterministic 혹은 Non Deterministic
모든 함수의 인자는 IN 파라미터
CREATE FUNCTION 사용
Trigger이란?
INSERT/DELETE/UPDATE 실행 전후에 특정 작업을 수행하는 작업을 수행하는 것
대상 테이블 지정 필요
CREATE TRIGGER 명령을 사용
NEW/OLD modifier
NEW는 INSERT와 UPDATE 시
OLD는 DELETE와 UPDATE 시
CREATE TRIGGER 트리거이름
{BEFORE | AFTER} {INSERT | UPDATE | DELETE}
ON table_name FOR EACH ROW
trigger_body;
[예시] 중요 테이블의 경우 감사(audit)가 필요
레코드에 변경이 생길 때마다(BEFORE) 변경전(OLD)의 레코드를 저장하는 트리거
성능 튜닝: Explain SQL과 Index 튜닝
Explain SQL
SELECT/UPDATE/INSERT/DELETE 등의 쿼리가 어떻게 수행되는지 내부를 보여주는 SQL 명령
MySQL이 해당 쿼리를 어떻게 실행할지 Execution Plan을 보여줌. 이를 바탕으로 느리게 동작하는 쿼리의 최적화가 가능해짐
-- EXPLAIN
EXPLAIN SELECT
-- 서술
Index
Index는 테이블에서 특정 찾기 작업을 빠르게 수행하기 위해서 MySQL이 별도로 만드는 데이터 구조를 말함.
Primary Key나 Foreign Key로 지정된 컬럼은 기본적으로 Index를 갖게 됨.
INDEX와 KEY는 동의어
Index는 SELECT/DELETE/JOIN 명령을 빠르게 하지만, 대신 INSERT/UPDATE 명령은 느리게 하는 단점이 존재
테이블에 너무 많은 인덱스를 추가하면, 인덱스의 로딩으로 인한 오버헤드로 인해 시스템이 전체적으로 느려질 수 있음.
CREATE TABLE시 지정 가능(컬럼 속성)
-- 테이블 생성하면서 하는 방법
CREATE TABLE example (
id int not null auto_increment,
index_col VARCHAR(20),
PRIMARY KEY(id),
INDEX index_name(index_col)
);
-- 생성된 테이블을 ALTER로 수정하면서 하는 방법
ALTER TABLE testalter_tbl ADD INDEX(column1);